iPAS AI應用規劃師 考試重點
L22403 大數據在生成式 AI 應用
主題分類
1
大數據對生成式AI模型訓練的必要性
2
用於訓練生成式AI的大數據類型
3
數據預處理與特徵工程
4
大數據驅動的內容生成應用
5
數據增強與合成數據生成
6
分散式訓練與基礎設施
7
數據偏見與公平性問題
8
評估指標與實際挑戰
#1
★★★★★
生成式AI (GenAI) 對大數據的依賴
核心概念
生成式人工智慧 (Generative Artificial Intelligence, GenAI) 模型,尤其是大型語言模型 (LLM) 和擴散模型 (Diffusion Models),需要極其龐大的數據集進行訓練。
原因:
原因:
- 學習複雜模式:模型需要從海量數據中學習語言結構、語義關係、圖像風格、物理規律等複雜模式。
- 提升泛化能力:數據量越大、越多樣,模型的泛化能力通常越強,能生成更合理、更多樣的內容。
- 模型規模:現代 GenAI 模型(如 GPT, Stable Diffusion)參數數量巨大(數十億甚至數兆),需要相應規模的數據才能有效訓練。
#2
★★★★
預訓練 (Pre-training) 中的大數據角色
核心概念
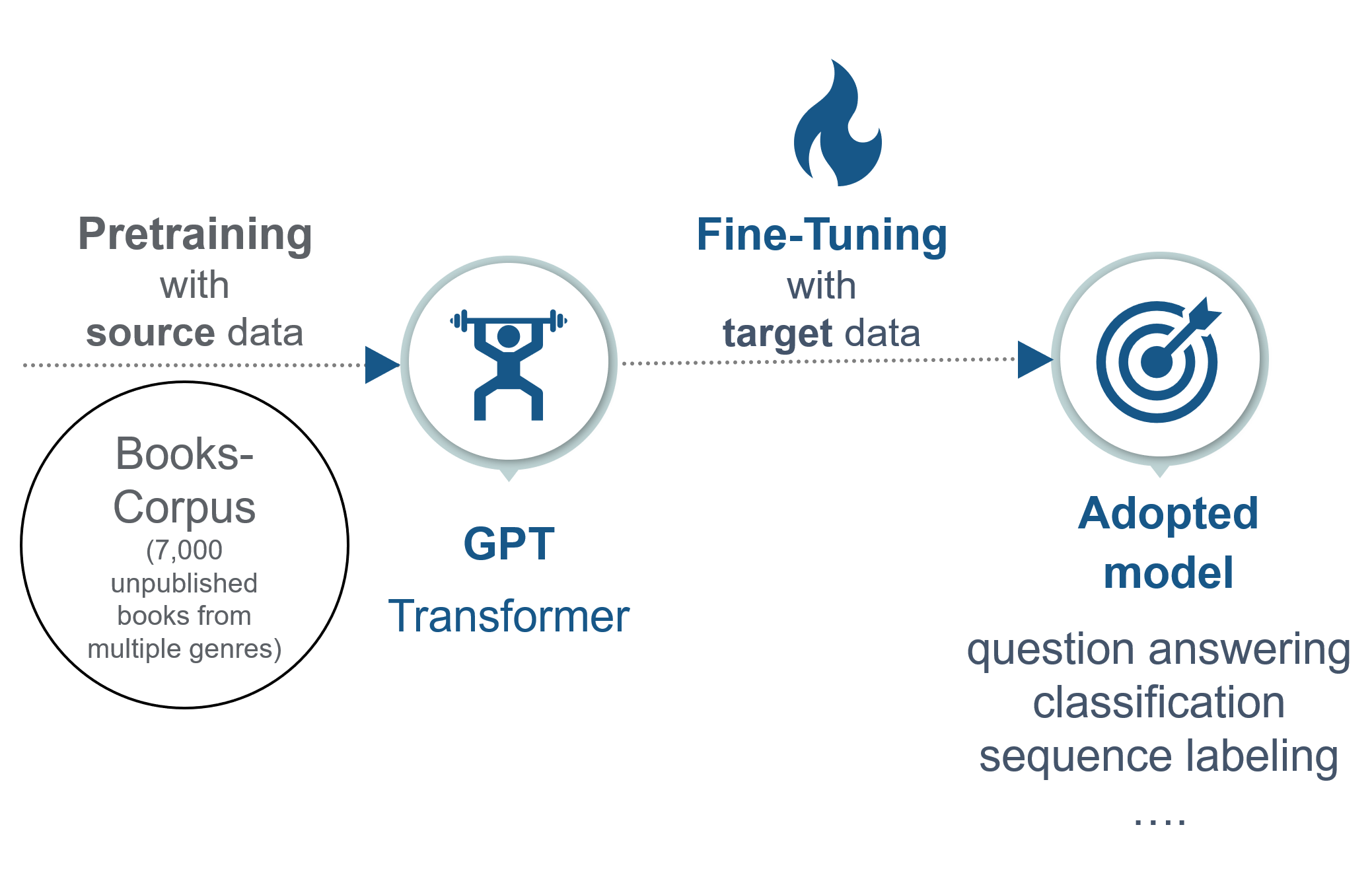
許多基礎模型 (Foundation Models) 採用預訓練階段,在大規模、無標註或弱標註的數據集上進行學習。
目的:讓模型學習通用的知識和表示能力。
數據來源:通常來自網際網路,如維基百科 (Wikipedia)、書籍、程式碼、網頁文本、圖像-標題對等。
這個階段對數據量和多樣性的要求最高,是大數據發揮關鍵作用的環節。
目的:讓模型學習通用的知識和表示能力。
數據來源:通常來自網際網路,如維基百科 (Wikipedia)、書籍、程式碼、網頁文本、圖像-標題對等。
這個階段對數據量和多樣性的要求最高,是大數據發揮關鍵作用的環節。
#3
★★★
微調 (Fine-tuning) 與領域特定數據
核心概念
在預訓練之後,通常會使用規模較小、但更具針對性的標註數據集對模型進行微調,以適應特定任務或領域。
雖然數據量級不如預訓練,但數據質量和相關性至關重要。
大數據技術仍可用於收集、處理和管理這些微調數據集,特別是對於需要大量特定領域知識的任務。
雖然數據量級不如預訓練,但數據質量和相關性至關重要。
大數據技術仍可用於收集、處理和管理這些微調數據集,特別是對於需要大量特定領域知識的任務。
#4
★★★★★
用於訓練大型語言模型 (LLM) 的數據類型
核心概念
訓練 大型語言模型 (Large Language Models, LLM) 需要海量的文本數據:
- 網頁文本:如 Common Crawl 數據集,包含大量網頁內容。
- 書籍:如 Google Books, Project Gutenberg。
- 學術論文:如 arXiv。
- 程式碼:如 GitHub。
- 對話數據:如社交媒體、論壇討論。
- 百科知識:如 Wikipedia。
#5
★★★★
用於訓練圖像生成模型的數據類型
核心概念
訓練文本到圖像 (Text-to-Image) 模型(如 Stable Diffusion, Midjourney)需要大量的圖像-文本對 (Image-Text Pairs) 數據集。
數據來源:
數據來源:
- 網路上帶有替代文本 (Alt-text) 或標題 (Caption) 的圖像。
- 大型開源數據集如 LAION-5B。
- 特定領域的圖像數據庫。
#6
★★★
多模態數據 (Multimodal Data) 的應用
核心概念
現代 GenAI 模型越來越多地處理多模態數據,即結合多種數據類型(如文本、圖像、聲音、影片)。
例如:
例如:
- 訓練能夠理解圖像並生成描述性文本的模型。
- 訓練能夠根據文本提示生成影片或音樂的模型。
#7
★★★★
生成式AI 的數據預處理關鍵步驟
核心概念
為訓練 GenAI 模型準備大數據集需要仔細的預處理:
- 數據清洗:去除低質量內容(如重複、亂碼、廣告、仇恨言論)、處理個人身份訊息 (PII)。
- 格式轉換與標準化:統一數據格式,如文本編碼、圖像大小。
- 文本分詞 (Tokenization):將文本切分成模型可以處理的單元(詞、子詞)。
- 數據去偏 (Debiasing):嘗試減少數據中存在的社會偏見。
- 數據過濾:根據特定標準篩選數據,如去除不符合要求的圖像-文本對。
#8
★★★
特徵工程 (Feature Engineering) 在生成式AI中的角色演變
核心概念
傳統機器學習嚴重依賴手動特徵工程。
對於大型生成式模型(特別是深度學習模型),模型傾向於自動從原始數據中學習有效的表示(特徵),手動特徵工程的角色相對減弱。
然而,在某些場景下仍然重要:
對於大型生成式模型(特別是深度學習模型),模型傾向於自動從原始數據中學習有效的表示(特徵),手動特徵工程的角色相對減弱。
然而,在某些場景下仍然重要:
- 在數據預處理階段提取結構化訊息(如從文本中提取元數據)。
- 為特定任務設計輸入提示 (Prompt Engineering) 可視為一種新的特徵工程形式。
- 在微調階段可能需要針對特定領域構建特徵。
#9
★★★★
大數據驅動的文本生成應用
核心概念
基於海量文本數據訓練的 LLM 可以應用於多種文本生成任務:
- 內容創作:寫作文章、郵件、廣告文案、劇本等。
- 程式碼生成:根據自然語言描述生成程式碼。
- 文本摘要:自動生成長文本的摘要。
- 機器翻譯:在不同語言之間進行翻譯。
- 問答系統與聊天機器人 (Chatbot)。
#10
★★★★
大數據驅動的圖像/視覺生成應用
核心概念
基於大規模圖像-文本對數據訓練的模型可以:
- 文本到圖像生成 (Text-to-Image Generation):根據文本描述生成圖像。
- 圖像編輯 (Image Editing):根據指令修改現有圖像(如風格轉換、物體添加/移除)。
- 圖像超解析度 (Image Super-Resolution):提高低解析度圖像的清晰度。
- 圖像修復 (Image Inpainting):填補圖像中缺失或損壞的部分。
#11
★★★
個性化內容生成 (Personalized Content Generation)
核心概念
結合用戶行為數據(如瀏覽歷史、購買記錄、偏好設置)和生成式AI,可以為每個用戶生成定制化的內容。
例如:
例如:
- 個性化的產品推薦描述。
- 定制化的新聞摘要或郵件。
- 根據用戶喜好生成的音樂播放列表或故事。
#12
★★★★
數據增強 (Data Augmentation)
核心概念
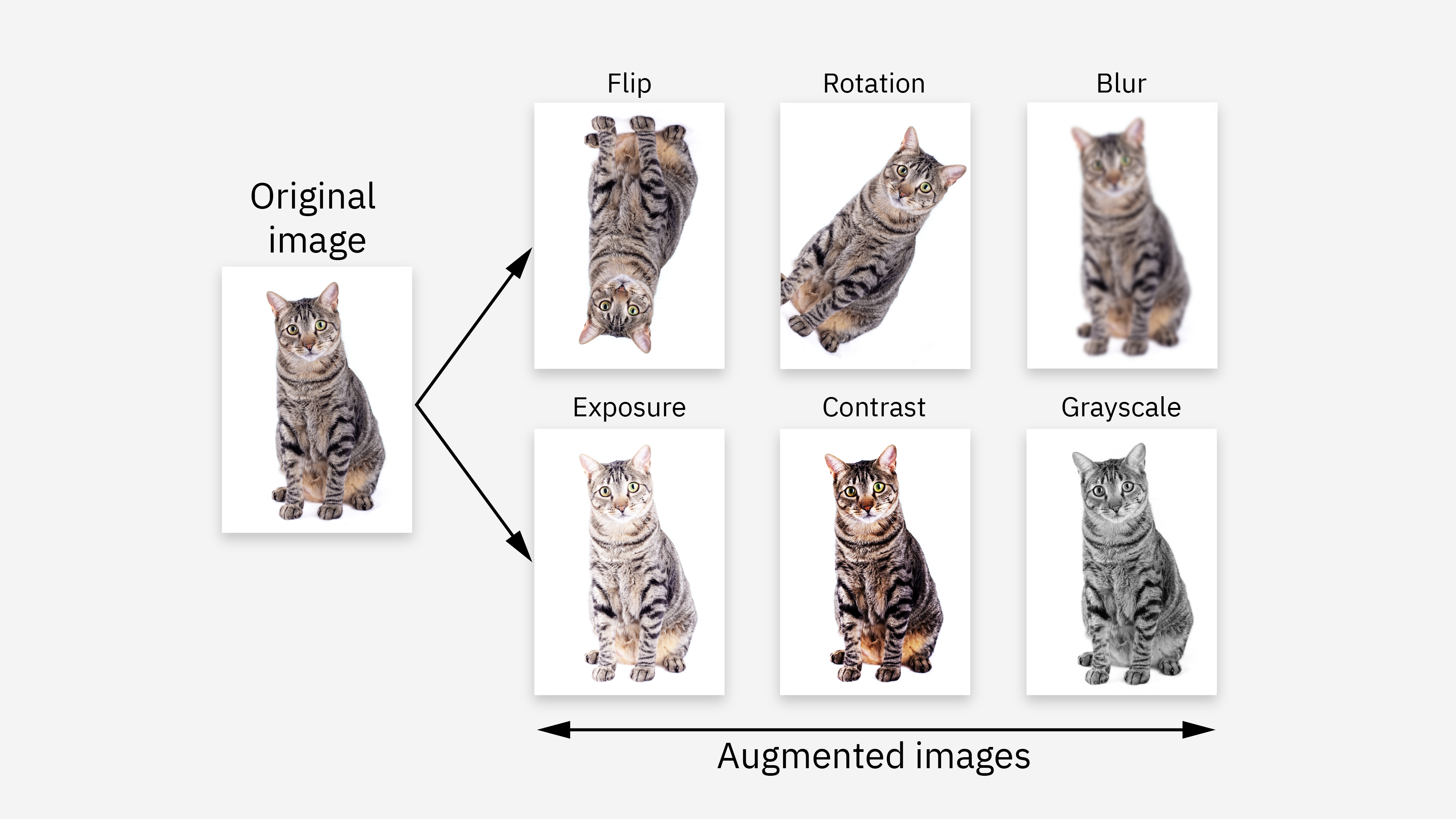
數據增強是指通過對現有數據進行變換來人工增加訓練數據量和多樣性的技術。
對於圖像數據,常用方法包括:旋轉、翻轉、縮放、裁剪、改變亮度/對比度、添加噪聲。
對於文本數據,方法包括:同義詞替換、回譯 (Back-translation)、隨機插入/刪除。
目的:提高模型的穩健性 (Robustness) 和泛化能力,減輕過擬合,尤其是在標註數據有限的情況下。
對於圖像數據,常用方法包括:旋轉、翻轉、縮放、裁剪、改變亮度/對比度、添加噪聲。
對於文本數據,方法包括:同義詞替換、回譯 (Back-translation)、隨機插入/刪除。
目的:提高模型的穩健性 (Robustness) 和泛化能力,減輕過擬合,尤其是在標註數據有限的情況下。
#13
★★★★★
合成數據生成 (Synthetic Data Generation)

核心概念
合成數據是指人工生成而非通過直接測量獲得的數據。生成式AI 模型(如 生成對抗網路 GAN, 變分自編碼器 VAE, 擴散模型)本身就可以用來生成合成數據。
應用場景:
應用場景:
- 擴充數據集:當真實數據稀缺或難以獲取時。
- 保護隱私:生成與真實數據分佈相似但不包含敏感訊息的合成數據。
- 處理不平衡數據:生成少數類的合成樣本。
- 模擬:生成用於模擬或測試的數據。
#14
★★★★
訓練大規模生成式模型的計算基礎設施需求
核心概念
訓練大型 GenAI 模型需要龐大的計算資源:
- 大量高性能計算單元:通常是圖形處理器 (GPU) 或專用 AI 加速器(如 TPU),需要數百甚至數千個。
- 高速網路互連:用於節點間的數據傳輸和參數同步。
- 大規模儲存系統:用於存儲海量的訓練數據和模型檢查點。
- 高效的分散式訓練框架:如 PyTorch Distributed, TensorFlow Distributed, Horovod。
- 資源調度和管理系統:如 Kubernetes, Slurm。
| 處理器類型 | 中央處理器 (Central Processing Unit) |
圖形處理器 (Graphics Processing Unit) |
神經網路處理器 (Neural Processing Unit) |
張量處理器 (Tensor Processing Unit) |
|---|---|---|---|---|
| 主要用途 | 通用計算 | 圖形處理/並行計算 | 神經網路運算 | 張量運算 |
| 架構特點 | 少量強大核心 | 大量小型核心 | 專用AI加速器 | 專用矩陣運算單元 |
| AI運算效率 | 低 | 中高 | 高 | 極高 |
| 功耗效率 | 中 | 中低 | 高 | 極高 |
| 主要廠商 | Intel, AMD | NVIDIA, AMD | 華為, 高通 |
#15
★★★★
雲端平台 (Cloud Platforms) 在生成式AI訓練中的作用
核心概念
雲端平台(如 AWS, Google Cloud, Microsoft Azure)為訓練大型 GenAI 模型提供了彈性的、可擴展的基礎設施。
優勢:
優勢:
- 按需獲取大量計算資源(GPU/TPU)。
- 提供託管的分散式儲存(如 S3, GCS, Azure Blob Storage)。
- 提供託管的機器學習平台和服務,簡化訓練流程。
- 按使用量付費,降低初始投資。
#16
★★★★★
數據偏見 (Data Bias) 對生成式AI的影響
核心概念
如果用於訓練 GenAI 的大數據本身存在偏見(如性別、種族、地域偏見),模型很可能會學習並放大這些偏見,導致生成帶有歧視性或刻板印象的內容。
例如:
例如:
- 生成將特定職業與特定性別關聯的文本。
- 生成符合主流審美標準但缺乏多樣性的圖像。
#17
★★★★
處理數據偏見的策略
核心概念
應對數據偏見的方法:
- 數據收集階段:努力收集更具代表性、更多樣化的數據。
- 數據預處理階段:使用算法檢測和修正數據中的偏見(如重採樣、重加權)。
- 模型訓練階段:採用公平性感知 (Fairness-aware) 的訓練算法或正則化項。
- 模型評估階段:使用公平性指標評估模型在不同群體上的表現。
- 後處理階段:對模型生成結果進行過濾或修正。
#18
★★★
評估生成式模型的挑戰
核心概念
評估 GenAI 模型(特別是生成內容的質量)比評估傳統判別式模型更困難,因為“好”的標準通常是主觀的。
常用評估方法:
常用評估方法:
- 自動評估指標:
- 文本:BLEU, ROUGE (用於翻譯/摘要), 困惑度 (Perplexity)。
- 圖像:FID (Fréchet Inception Distance), IS (Inception Score)。
- 人工評估 (Human Evaluation):由人類評估者對生成內容的流暢性、相關性、創造性、真實性等進行評分。成本高、耗時、主觀性強。
#19
★★★★
大數據與生成式AI的幻覺 (Hallucination) 問題
核心概念
幻覺是指生成式模型產生看似合理但實際上是錯誤的、無意義的或與源數據不符的內容。
原因可能包括:
原因可能包括:
- 訓練數據中的噪聲或錯誤訊息。
- 模型過度擬合了某些模式。
- 模型試圖填補知識空白。
#20
★★★
數據來源的版權與合規性
核心概念
使用大規模數據集(尤其是來自網路的數據)訓練 GenAI 模型引發了版權 (Copyright) 和數據使用合規性的問題。
考量點:
考量點:
- 訓練數據是否包含受版權保護的材料?
- 數據爬取和使用是否符合服務條款和相關法律(如 GDPR)?
- 模型生成的內容是否可能侵犯他人版權?
沒有找到符合條件的重點。
↑